Pyflash
From Openmoko
Contents |
Description
 This is a flashcard application written in PyGTK for learning words, sentences and other factual data. It supports UTF-8 and has been successfully tested with Japanese, Arabic and Devanagri (Nepali and Hindi) characters. It also runs on all desktops and laptops that have PyGTK installed. For download, see package at OPKG.org and project at SourceForge.
This is a flashcard application written in PyGTK for learning words, sentences and other factual data. It supports UTF-8 and has been successfully tested with Japanese, Arabic and Devanagri (Nepali and Hindi) characters. It also runs on all desktops and laptops that have PyGTK installed. For download, see package at OPKG.org and project at SourceForge.
To get to the source, see SVN or download the opk file and do an 'ar x pyflash.opk', then you will get a bunch a files. One of them is a .tar.gz which holds the source code. for the moment, this is the only way to get to the source.
Screenshots
- Four standard ways of using the application

normal portrait

fullscreen portrait
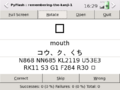
normal landscape
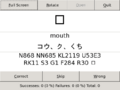
fullscreen landscape




Note that the 'Open' button is disabled in fullscreen mode, because the popup will be in the background and user is unable to control the dialog that has the current focus.
Sets
At the moment the following flashcard sets are available inside the pyflash package:
- Source kanjidic collection which is shipped with the gjiten package. This set is superseding the Remembering the Kanji flashcards part 3. Several decks are available:
- kanjidic-g1, 80 flashcards, only first grade kanji (first year in school)
- kanjidic-g2, 160 flashcards, only second grade kanji
- kanjidic-g3, 200 flashcards, only third grade kanji
- kanjidic-g4, 200 flashcards, only fourth grade kanji
- kanjidic-g5, 185 flashcards, only fifth grade kanji
- kanjidic-g6, 181 flashcards, only sixth grade kanji
- kanjidic-g8, 939 flashcards, only eight grade kanji
- kanjidic-g9, 287 flashcards, only nineth grade kanji
- kanjidic-g-, 4123 flashcard, no grade kanji (more difficult)
- kanjidic, 6355 flashcards, all kanji from this source
- Source Wikipedia collection of alphabets. several decks are available:
- hiragana-basic, 74 flashcards
- hiragana-contracted, 38 flashcards
- hiragana, 112 flashcards, basic and contracted
- katakana-basic, 73 flashcards
- katakana-contracted, 39 flashcards
- katakana, 175 flashcards, basic and contracted
- katakana-extended, 63 flashcards
- both-hiragana-katakana, 287 flashcards
Format
An example of the versatile format based upon Remembering the Kanji is given here:
口;N868 U53E3;S3 G1 F284 口:mouth:コウ、ク、くち
日;N2097 U65E5;S4 G1 F1 日:day|sun|Japan:ニチ、ジツ、ひ、-び、-か
癒;N3081 U7652;S18 G8 F1667 疒:healing|cure|quench (thirst)|wreak:ユ、い(える)、いや(す)
The part before the first : is the question. There, the characters before the first ; is the actual question. e.g. 口 or 日. Other characters of that part form the explanation of the question. Extra ; in there will trigger a new line in the explanation as can be seen in the screenshots. The part in between the middle two : is the answer and the part after the last : is the explanation or pronunciation of the answer.
Note that the answer and pronunciation will only appear after tapping the text area of the application. Here the explanation of the question is used to flood the screen with all sort of data, e.g. U53E3 is the unicode ID and the kanji at the end is the radical used for quick look up in dictionaries.
ChangeLog
| version | date | author | comments |
|---|---|---|---|
| 0.1 | 2006-02-01 | Noufal Ibrahim <noufal@nibrahim.net.in> | initial release,arabic |
| 0.2 | 2007-??-?? | ezuall <ezuall@gmail.com> | openmoko,pronunciation |
| 0.3 | 2009-04-06 | Pander <pander@users.sourceforge.net> | openmoko,kanji support |
| 0.4 | 2009-04-20 | Pander <pander@users.sourceforge.net> | misc. improvements |
| 0.5 | 2009-06-16 | Pander <pander@users.sourceforge.net> | persistent deck |